
Sematext Monitoring Alternatives, a full-stack IT infrastructure monitoring tool, provides real-time visibility into on-premises and cloud deployments. You can also observe how well your infrastructure is performing by monitoring an eye on its inventory, servers, containers, processes, events, databases, & more. You can use it for receptacle infrastructure monitoring to gain access to containerized programmes running in Docker or orchestration platforms like Kubernetes, Docker Swarm, and Nomad.
Top 12 Sematext Monitoring Alternatives In 2023
In this article, you can know about Top 12 Sematext Monitoring Alternatives In 2023 here are the details below;
Sematext Monitoring enables automated discovery. The Sematext Agent searches your surroundings for services that could be integrated within the product itself to speed up onboarding. Comprehensive anomaly detection is offered by this solution, along with access to third-party infrastructure alerting systems like PagerDuty, Opsgenie, Splunk On-Call (formerly VictorOps), and webhooks. It also offers you a consolidated reporting view that combines alarms and logs in a single pane to make it simple for you to understand the state of your environment. This is another infrastructure monitoring tools. Also check automation testing tools
Pros
- Over a hundred integrations for popular application stacks, such as MongoDB, MySQL, Apache Spark, and Apache Cassandra
- Quick onboarding with the lightweight, open-source Sematext Agent
- Monitors logs and events, correlating them to provide details on the infrastructure’s state.
- Compiles a list of servers and monitors it for discrepancies, outdated software, and deviations.
- Monitoring processes to spot performance bottlenecks
Cons
- Limited transaction tracing support
- There is no completely operational profiler
1. The Elastic stack

The Elastic Stack (ELK Stack) monitoring solution is made up of three open-source projects: Elasticsearch, Logstash, and Kibana. Elasticsearch is in charge of search & analytics, with Logstash assisting with the injection and transformation of data from numerous sources before it is delivered to Elasticsearch. Kibana makes it possible to visualise data that Elasticsearch has examined through the use of graphs and charts. These capabilities can be used to provide measurements obtained from multiple sources inside your infrastructure and insights into the condition of your environment.
The integration for infrastructure monitoring is made possible by the Metricbeat module, which correlates metrics from several sources like servers, Docker containers, Kubernetes, and more. The module enables Kibana to use index patterns to visualise the state of the infrastructure. You may also set up alerts for metrics- and index-based criteria, and send notifications to recipients via email, Slack, Microsoft Teams, or other third-party integrations.
Pros
- Possibility of utilising a hosted solution or hosting ELK locally
- The Kibana dashboard’s ability to show CPU/memory utilisation and information at the process level.
- Data visualisation, examination, and customisation in real-time to give in-depth information
- Analyzes telemetry data from distributed infrastructures in real-time.
- Resources for a variety of scripting and programming languages
Cons
- Complicated multi-step deployment
- To ensure data usability, high availability, and resilience, a comprehensive infrastructure design is necessary.
2. Prometheus
This is another infrastructure monitoring tools. An open-source infrastructure monitoring tool called Prometheus that was created by former Google workers was initially intended to monitor heavily containerized environments. Time-series data are used. Prometheus should be able to periodically examine an HTTP metrics endpoint exposed by the services it monitors. Access to numerous metrics and their current values should be made available using this API. In some cases, it is not possible to alter the containerized service to send the metrics that Prometheus requires. The metrics can then be gathered by combining the container service with the Prometheus exporter as a sidecar pod container.
Prometheus has a single node-based configuration & does not need distributed storage in the architecture. It also uses Prometheus Query Language (PromQL) for real-time data aggregation and querying of monitoring data. The Alertmanager generates and distributes alerts based on predetermined alerting rules.
Pros
- Utilizes numerical time-series data, which is ideal for service-oriented, dynamic, and microservice-based architectures
- A stand-alone service that is not dependent on a network or external storage
- Runs without a lot of infrastructure.
- Excellent integration for Kubernetes infrastructure monitoring
- Visualization using Grafana integration
Cons
- Native long-term archiving and automated scalability may be required in big enterprise contexts, however neither feature is present.
- Integration with external dashboards like Grafana is necessary for visualisation (involves additional configuration overhead)
3. Zabbix
Zabbix is among the most popular open-source infrastructure monitoring tools out there. It’s a versatile solution with a range of monitoring capabilities, including, to name a few, network, server, cloud, application, and database monitoring. Zabbix has a variety of visualisation tools that you may use to evaluate the condition of your infrastructure. You can utilise the alerting and remediation features of the programme to identify and address issues as they arise.
Zabbix works with a number of operating systems and gathers vital information such as CPU, memory, and network utilisation (including Windows, Linux, Unix, etc.). You can use its pre-built templates for the automated discovery of components to be monitored, with the opportunity to construct new templates if necessary. Zabbix can be set up to issue alerts in response to predefined triggers and transmit them by email, SMS, script alerts, webhooks, and other means.
Pros
- A small, lightweight agent that the Zabbix server centrally maintains
- Broad-based support for all essential infrastructure components
- Support from the community and industry is strong for open source
- Efficient use of the Zabbix API to interface with third-party apps
- Infrastructure visibility in a single pane with scalable dashboards, graphs, and reports
Cons
- Difficult initial configuration and deployment
There isn’t a hosted SaaS alternative.
4. SolarWinds’ Server & Application Monitor (SAM)
The comprehensive monitoring offered by SAM (SolarWinds Server and Application Monitor) includes both your on-premises and cloud-based IT infrastructure. The community has provided more integration templates, and more than 1,200 apps and systems are supported out of the box. With the help of the application, you may monitor various components of the infrastructure using WMI, SNMP, PowerShell, REST API, and other tools. This is another infrastructure monitoring tools. Also check translation management software tools
SAM contains preconfigured OS monitoring configurations for Windows and Linux, enabling faster onboarding and performance monitoring. Additionally, you don’t need a variety of IT monitoring tools. SAM tracks performance, hard-drive status, fan status, power supply, and temperature for server hardware from many manufacturers (Dell, HP, IBM, etc.) from a single console. This also holds true for alerting and reporting. Managers can also obtain data for both monitored and unmonitored WMI and SNMP processes via the web portal without connecting into the servers thanks to Real-Time Process Explorer (RTPE).
Pros
- Continuous server monitoring and cross-stack monitoring of data
- Charts of capacity and forecasts to aid in long-term capacity planning
- Monitors general server and application performance, uptime, and hardware issues
- Monitors Docker container performance metrics including CPU, memory, and uptime
- Data visualisation with basic dashboards
Cons
- Integration with additional SolarWinds tools
- Complex configuration resulting from a large number of components
5. N-able RMM
N-able RMM, with its self-healing properties, can be quickly scaled to monitor thousands of infrastructure components and aid in the early detection and repair of problems. It provides the remote monitoring, management, patching, automation, and other features that managed service providers require to get visibility into the varied IT environments of the clients they manage.
Utilizing the N-central probe technology, N-able RMM enrols and adds devices that will be tracked. For managed service providers who work with several clients, technology mapping provides a rapid overview of each customer’s environment. This tool’s more than 100 prewritten automated tasks, as well as templates for new actions, can speed up the monitoring and remediation operations. Granular controls can be enabled if necessary, even when best practises monitoring and alerting are already configured automatically.
Pros
- Easy onboarding for new customers
- Awareness and perceptions based on data obtained from sources
- Automated monitoring templates and scripting to speed up monitoring
- Works as a hosted or on-premises solution.
- Using API integration to build an adaptable monitoring architecture
Cons
- Constructed with fewer features for MSPs
- Not appropriate for large companies with varying workloads
6. Datadog’s Infrastructure Monitoring
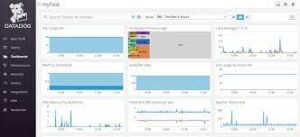
Your system’s infrastructure components’ on-premises and cloud performance status are visible to you thanks to Datadog Infrastructure Monitoring. To monitor the performance of your application stack, containers, virtualization platform, and other components, use Datadog’s thousands of built-in infrastructure metrics. The tool uses an open-source agent to handle more than 450 integrations, including well-known stacks like Kubernetes, Docker, and Apache Kafka. This is another infrastructure monitoring tools.
You may drill down to the state of particular hosts using Datadog Infrastructure monitoring, and you’ll get consolidated dashboards that provide you visibility into the health of your infrastructure. It provides autonomous anomaly detection and intelligent warning technology.
Pros
- Has all required infrastructure monitoring criteria (metrics, logs, security, etc.)
- Modifiable integrations with the Datadog API
- A unified monitoring experience for on-premises and cloud applications using its open-source agent.
- Visualization of relevant infrastructure components in the host map quality
- Customizable dashboards for communicating key insights about your infrastructure health
Cons
- Complex setup that requires a steep learning curve from new users
- Only has a few pre-built dashboards.
7. ManageEngine OpManager
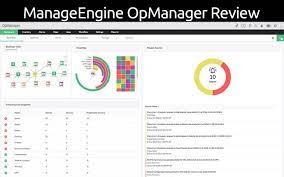
This is another infrastructure monitoring tools. Real-time monitoring of grids, physical and virtual servers, warehouse devices, and other items is supported by ManageEngine OpManager, a dependable infrastructure monitoring solution. In addition to routine monitoring of hosts and virtual machines in your infrastructure and customizable dashboards with more than 200 performance widgets, the software delivers a comprehensive view of overall network performance.
OpsManager can be & for proactive server monitoring using a number of thresholds (i.e., the performance can be checked at various levels). The application can automatically map all services that are running on Linux and Windows servers to availability and response-time monitoring.
Pros
- A thorough examination of the network’s performance indicators, such as latency, packet loss, errors, and speed
- Process and system health monitoring using SNMP, WMI, and CLI
- Agentless monitoring for VMware and Hyper-V WMI-based monitoring
- More than 40 built-in indicators for VMware and more than 70 for Hyper-V
Monitoring and reporting of errors
Cons
- Specific to network monitoring, with little assistance for other infrastructure components
- No hosted version
8. PRTG Network Monitor
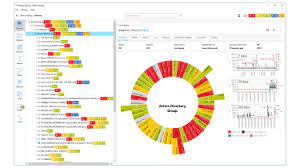
You have considerable network, server, virtual machine, and application monitoring capabilities with the help of a solution for infrastructure monitoring called PRTG Network Monitor. There are options for agent-based and agentless monitoring. Agentless monitoring uses a variety of technologies to collect metrics data, including WMI, SNMP, SSH, and NetFlow. Also check mock API
PRTG offers a dashboard that lets you examine alerts, outages, and warnings all at once for high-level visibility. Additionally, it has simple-to-use business process sensors that allow you to monitor the IT infrastructure elements employed in a specific business process. The ability of long-term planning to monitor infrastructure capacity, which examines infrastructure capacity and identifies bottlenecks, is beneficial.
Pros
- Simple setup with a personalised database
- Possibility of using a hosted version or installing it locally
- A built-in map designer to view the network and connected components
- Out-of-the-box reports that may be customised to identify performance issues
- Customizable notifications delivered via scripts, pop-up messages, SMS, email, and other channels.
Cons
- There is no Linux installation support.
- Expensive licencing for large-scale sensor-based systems
9. Nagios
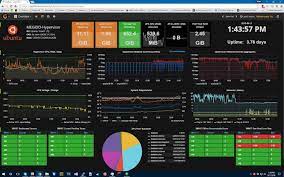
Nagios was one of the first infrastructure monitoring tools, and it is still in use today. It is available as both an open-source programme (Nagios Core) and a for-profit business solution (Nagios XI). The Linux-based Nagios Core is especially favoured because of its architecture, which enables it to be expanded with both official and independently produced custom plugins. This is another infrastructure monitoring tools.
Nagios is a tool for centralised monitoring of infrastructure components such software, operating systems, system metrics, and other software. Its extensive reporting capabilities, which include history information and availability reports that may be increased through add-ons from other parties, are another benefit. Nagios’ multi-tenant design and user-specific view customizations help you quickly locate outages. Additionally, it notifies you via email or SMS when something goes wrong.
Pros
- An extendable architecture based on plugins
- Constant infrastructure monitoring and deployment with great accessibility
- Web-based single-pane visibility of IT infrastructure state
- Automated remediation capabilities for event handlers
- Having access to open-source software’s source code
Cons
- The open-source, free version lacks a few features.
- Several add-ons are necessary for the full range of capabilities.
10. WhatsUp Gold
This is another infrastructure monitoring tools. WhatsUp Gold is a network monitoring system for full-stack monitoring that may be supplemented with modules to monitor apps and infrastructure components. For your virtual infrastructure that is hosted by VMware or Hyper-V, it provides extensive monitoring options. WhatsUp Gold offers data from a single interface on host and guest CPU, memory, disc, and network usage.
This tool monitors network performance as well as how much bandwidth each component of your application uses. Additionally, Windows Logs and Syslog may be integrated and monitored, giving you valuable insight into the condition of your infrastructure. To better understand the condition of your infrastructure, WhatsUp Gold may also be used for availability and performance monitoring.
Pros
- Comprehensive library of extensible plugins
- Automated server inventory reporting
- Monitors server performance and is able to follow real-time migrations
- Threshold-based notifications sent through email, SMS, or slack.
- Individualized dashboards to monitor the condition of the infrastructure
Cons
- Installation is only available in the Windows environment.
- Accessible hosted services are unavailable.
11. New Relic
You have access to robust dashboard capabilities and visibility into the performance of your infrastructure components thanks to New Relic, a full-stack monitoring solution. Instead of switching between numerous programmes, New Relic allows you to monitor data from logs, infrastructure, applications, serverless operations, and more from a single tool. Using New Relic, you can monitor important host metrics like CPU, RAM, disc, and network status in real-time.
Infrastructure monitoring data may be easily tracked and searched for using New Relic’s insights function. Dashboards are created automatically by new infrastructure connectors, increasing the insights from these integrations. This is another infrastructure monitoring tools.
Pros
- The ability to troubleshoot service performance issues depending on tool interface.
- Real-time and artificial user monitoring
- Consistently monitoring infrastructure across hybrid platforms
- Distributed tracing provides end-to-end transparency.
- Offers the choice to employ pre-built alert policies or custom alerts with anomaly detection.
Cons
- Complex and unpredictable UI
- Because the platform cannot manage agents, there is a huge administrative burden.
12. Dynatrace

This is another infrastructure monitoring tools. Dynatrace supplies a comprehensive monitoring platform that can cover your infrastructure in cloud, on-premises, and hybrid environments. Among these are host machines, servers, storage, networks, and Kubernetes clusters, to name a few. Each host has a single agent installed in order to collect monitoring data. This agent has the ability to watch over servers, programmes, services, databases, and more. You can enable the agent to carry out physical/virtual infrastructure-focused monitoring by enabling the infrastructure monitoring mode.
The Dynatrace stack can be implemented using either your own hybrid cloud or the hosted SaaS solution. Additionally, you may use Dynatrace to monitor host processes, RAM, storage, NIC metrics, CPU, and the VMware virtualization platform.
Pros
- Customizable dashboards for rapid and accurate data visualisation
- Flexible monitoring architecture with OneAgent SDK
- Monitoring integrations for OpenShift, Docker, and Kubernetes
- Discovering and mapping dependencies automatically
- Easy agent management utilising the tool’s user interface
Cons
- A challenging learning curve due to the tool’s complexity
- Reasonably high cost



